
|
Transcriber - A Tool for Segmenting, Labeling and Transcribing Speech
Transcriber is a tool for assisting the manual annotation of speech signals. It provides a user-friendly graphical user interface for segmenting long duration speech recordings, transcribing them, and labeling speech turns, topic changes and acoustic conditions. Transcriber is distributed as free software under GNU General Public License . Here is a list of Transcriber's main features. Transcriber is used in the SCoRE project for creating and editing time-aligned transcripts - these are XML documents that line up transcript text with the corresponding part of the audio recording. Most of our transcripts were produced with this free tool. Here is a snapshot. Wmatrix: Corpus Analysis and Comparison Tool Wmatrix is a software tool for corpus analysis and comparison. It provides a web interface to the USAS and CLAWS corpus annotation tools, and standard corpus linguistic methodologies such as frequency lists and concordances. It also extends the keywords method to key grammatical categories and key semantic fields. Click here for more information about Wmatrix's main features. We use Wmatrix to automatically tag our SCoRE corpus data by uploading the files to the Wmatrix server at Lancaster University, UK. The web server completes the automatic tagging process and the files are POS tagged by CLAWS and semantically tagged by USAS. The output then are converted to XML documents for later use. You can see a sample output. For detailed information about how we use Wmatrix tagged results for our corpus, you may want to read our SCoRE Working Manuals. MMAX: Multi-Modal Annotation in XML MMAX is an annotation tool used in SCoRE project to annotate our corpus data. The MMAX tool is a light-weight and highly customizable implementation of multi-level annotation of (potentially multi-modal) corpora. It is based on the assumption that any annotation can be simplified to sets of so-called markables carrying attributes and standing in certain relations to each other. Consequently, all a tool has to supply is efficient low-level support for the creation and maintenance of markables on different levels. Click here for more information about MMAX's main features. Here is a snapshot of how we use MMAX to annotate IRF patterns in the classroom interactions of SCoRE corpus. For detailed information about how we use MMAX to annotate IRF and other features of education discourse, you may want to read our SCoRE Working Manuals. 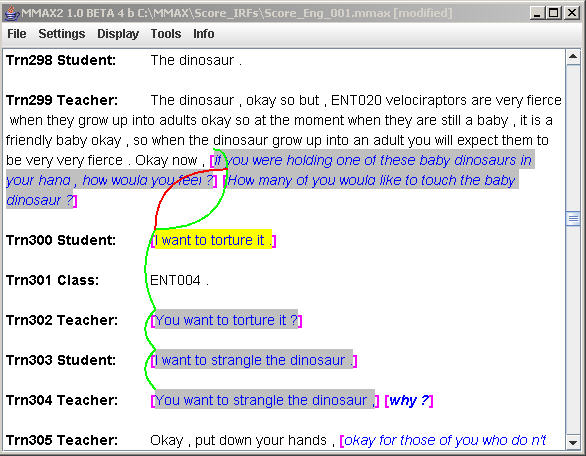
MMAX Checker: A Java Plugin to MMAX Annotation Tool MMAX Checker is an Java program we developed in-house for checking the annotation results of MMAX tool. As MMAX has a limited functions in this respect, we have to design this plugin to facilitate our annotators to check their output. It mainly has the following features: 1). Output MMAX annotation results in an intuitive and user-friendly interface; 2). Generate (possible) error list of the annotated files; 3). Provide statistical counts of each of the linguistic or discourse categories annotated in the files; 4). Extract annotated markables of each linguistic or discourse category in the scheme; and 5). Check and enhance inter-annotator agreement. Here is a snapshot of how we use MMAX Checker to extract IRF patterns annotated in MMAX tool. For detailed information about MMAX Checker, you may want to read our SCoRE Working Manuals. 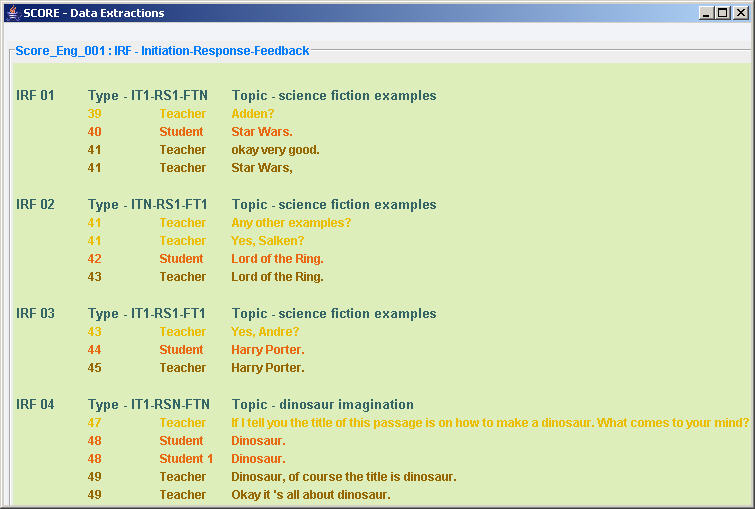
| |
Copyright@ 2006 SCoRE. All rights reserved. |
|